第二部 【企業情報】
第1 【企業の概況】
1 【主要な経営指標等の推移】
(注) 1.当社は連結財務諸表を作成しておりませんので、連結会計年度に係る主要な経営指標等の推移については記載しておりません。
2.持分法を適用した場合の投資利益については、当社は関連会社を有していないため記載しておりません。
3.1株当たり配当額及び配当性向については、配当を実施していないため、記載しておりません。
4.潜在株式調整後1株当たり当期純利益については、1株当たり当期純損失であり、また、新株予約権の残高はありますが、当社株式は非上場であるため期中平均株価を把握できませんので記載しておりません。
5.自己資本利益率については、当期純損失が計上されているため、記載しておりません。
6.当社株式は非上場であるため株価収益率を記載しておりません。
7.第6期から第8期については、キャッシュ・フロー計算書を作成していないため、キャッシュ・フローに係る各項目については、記載しておりません。
8.従業員数は就業人員であり、臨時従業員数(契約社員及びアルバイト・パート社員を含む、派遣社員は含まない)は、年間の平均雇用人員を〔 〕内に外数で記載しております。
9.第9期及び第10期の財務諸表については、「財務諸表等の用語、様式及び作成方法に関する規則」(昭和38年大蔵省令第59号)に基づき作成しており、株式会社東京証券取引所の有価証券上場規程第216条第6項の規定に基づき、金融商品取引法第193条の2第1項の規定に準じて、監査法人シドーの監査を受けております。なお、第6期、第7期及び第8期については「会社計算規則」(平成18年法務省令第13号)の規定に基づき算出した各数値を記載しております。また、当該各数値については、金融商品取引法第193条の2第1項の規定に基づく監査法人シドーの監査を受けておりません。
10.2024年7月11日開催の取締役会において、A種優先株式、B種優先株式、C種優先株式、D種優先株式及びD-1種優先株式のすべてにつき、定款に定める取得条項に基づき取得することを決議し、2024年7月29日付で自己株式として取得し、対価としてA種優先株式、B種優先株式及びC種優先株式1株につき普通株式1株を、D種優先株式及びD-1種優先株式1株につき普通株式2.34株(小数点以下第3位を四捨五入)をそれぞれ交付しております。また、当社が取得したA種優先株式、B種優先株式、C種優先株式、D種優先株式及びD-1種優先株式のすべてについて、同日付で消却しております。なお、当社は、2024年7月30日開催の臨時株主総会により、2024年7月31日付で種類株式を発行する旨の定款の定めを廃止しております。
11.2024年7月31日付で普通株式1株につき100株の割合で株式分割を行っておりますが、第9期の期首に当該株式分割が行われたと仮定し、1株当たり純資産額及び1株当たり当期純損失(△)を算定しております。
12.2024年7月31日付で普通株式1株につき100株の分割を行っております。そこで、東京証券取引所自主規制法人(現 日本取引所自主規制法人)の引受担当者宛通知「『新規上場申請のための有価証券報告書(Ⅰの部)』の作成上の留意点について」(平成24年8月21日付東証上審第133号)に基づき、第6期の期首に当該株式分割が行われたと仮定して算定した場合の1株当たり指標の推移を参考までに掲げると以下のとおりとなります。なお、第6期、第7期及び第8期の数値(1株当たり配当額については全ての数値)については、監査法人シドーの監査を受けておりません。
2 【沿革】
(注) 1.コミュニケーションデータを作成し(書き起こしし)、蓄積し、それらデータを基に能動的な業務を遂行することできるAI(人工知能)を指した表現として使用しています。
2.Large language Models(大規模言語モデル)の略称であり、大量のデータとディープラーニング(深層学習)技術によって構築された言語モデルのことを指します。
3.YuzuAIグループが構築した日本語LLMを評価するためのベンチマークであり、2023年10月時点において、開示されている各ベンチマークとの比較に基づいて記載しております。
3 【事業の内容】
当社は、「個人の記憶の永遠化・意思の再現・個人の価値の最大・永遠化により自律社会の実現を加速させるパーソナル人工知能」の開発を目指し、「ラボーロからオペラへ」と「私たちの存在を永久にする」の2つをMission(使命)に掲げ、創業より一貫して「P.A.I.」(パーソナル人工知能)の研究開発を行っております。「P.A.I.」(パーソナル人工知能)とは、私たち自身の意思をデジタル化し、それをクラウド上に配置してあらゆるデジタル作業をそのクローンにさせることを目的としたAIであり、当社は、全ての人が自分のAIを持つことによって、労働(Lavoro)から解放され、アーティスティックな営み(Opera)に没頭することができる世界を実現することを目指しています。これが実現することにより、現在多く見られる「労働集約型ビジネスモデル」から「知識集約型ビジネスモデル」へと転換が行われると考えております。

当社は、アカデミックのネットワークを活用し「P.A.I.」(パーソナル人工知能)の研究開発を進める一方で、その研究開発過程から生まれた対話エンジン(※)などの要素技術(※)や、機械学習(※)による個性モデル(※)構築などのノウハウを、AIの活用を検討するクライアントに提供してまいりました。また、2020年1月に、現在の当社収益の多くを占めるCommunication Intelligence(※)「AI GIJIROKU」の提供を開始するなど、上記技術を活用したAI Products事業や、戦略的パートナーとの連携により様々なクライアントに対してAIモデルを応用したAI Solutions事業を提供しております。
これらの製品を支える技術として、日本語の複雑な言い回しや専門用語を学習した当社独自開発の「LHTM-2」等の大規模言語モデル(LLM)(以下、「LLM」)(※)を保有しております。こちらは柔軟なカスタマイズが可能かつ個性化に対応しており、事実の正確性を担保した設計となっております。また、AI市場の拡大により、一層確保が難しくなっていくと考えられる計算リソースという点についても、分散コンピューティング(※)と分散ストレージ(※)の独自のインフラストラクチャー技術「Emeth」、「Stack」を保有しております。
(1) 当社及び当社技術の特徴・優位性
① 設立以降、技術を蓄積し続けてきたことによる先行優位性
当社は、2014年11月設立以降、一人ひとりに「P.A.I.」(パーソナル人工知能)を提供するという世界観の実現に向けて、研究開発を続けてまいりました。2015年より、「Personal Artificial Intelligence」「P A.I.」(2018年6月に同意義として「P.A.I.」)の商標を取得し、あらゆるテクノロジー分野のトップティアアカデミアとの連携を強化し、他社に先駆けて「P.A.I.」(パーソナル人工知能)に必要な独自の技術を蓄積してまいりました。研究開発の実施にあたっては、2016年のSeriesAラウンド以降、2022年から2023年に実施したSeriesDラウンドまでの調達資金も基に進めております。
以上より、昨今脚光を浴びる「パーソナルエージェント思想」の先駆者であること、また同分野における技術的な先行優位性があるものと自負しております。パーソナルエージェント思想とは、「人の非生産的労働からの解放」という目標のためAI技術を活用して人間の生活をより豊かで効率的にするための重要な「ツール」としての概念です。この思想は、人々が日常生活やビジネスの中で直面する繰り返しの作業や時間を要するタスクから解放され、より創造的で価値の高い活動に集中できるようにすることを目指しています。当社では、このパーソナルエージェント思想を実現するために、高度な自然言語処理技術や機械学習を用いたパーソナルエージェントの開発に取り組んでいます。これらの技術により、個々のユーザーのニーズに合わせたカスタマイズが可能となり、よりパーソナライズされたサービスの提供が実現します。当社は、その基盤となる技術であるLLMを自社開発してまいりましたが、それに基づいたプロダクト(2020年よりリリースし現在主要プロダクトとなっているCommunication Intelligence「AI GIJIROKU」を筆頭として、そのほか、PoC(Proof of Concept、概念実証。以下、「PoC」)により様々なビジネス上の課題を切り口としてソリューション展開する「altBRAIN」、「AIコールセンター」、「CLONEdev」など)の展開を皮切りに、売上を大きく拡大させております。

(注) 1.AI Products事業が立ち上がり始めた2020年度以降の売上高を記載しております。
2.2021年12月期以前の売上高については、監査法人シドーによる監査を受けておりません。
3.ジャフコグループ株式会社を頂点とする同社のグループ会社及び同社が投資助言を行うファンドを総称して、ジャフコグループと記載しております。
4.Vertex Holdings.が投資助言を行うファンドを総称して、Vertexグループと記載しております。
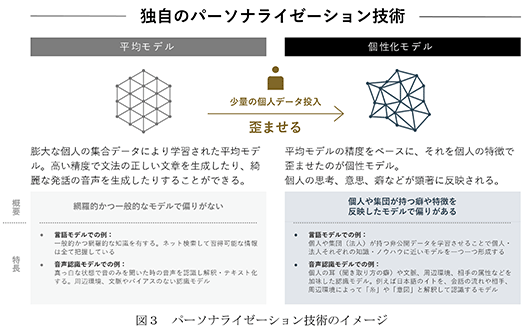
② 当社独自のパーソナライゼーション技術
一般的に、個々人にパーソナライズされたAIモデルを開発するためには、多くの学習データと学習時間を必要とすることから、クライアントへのサービス提供においては多額のコストが掛かると考えております。当社は、「P.A.I.」(パーソナル人工知能)を広くサービスとして普及するため、安価にパーソナライズされたモデルを提供できるよう研究を続けてまいりました。当社では、膨大な集合データにより学習された汎用的なエンジンである「平均モデル」を構築しております。「平均モデル」そのままでのサービス展開は行っておらず、「平均モデル」に、パーソナライズを行いたい対象のパーソナルデータ(例えばSNSやメール等のデータ)を学習させることで「平均モデル」を歪ませ、個人の思考、意思、癖などが反映される「個性モデル」を開発します。この際、当社の長年の技術により、学習に必要なパーソナルデータを極少量のデータで実現することが可能であり、これにより相対的に安価に「P.A.I.」(パーソナル人工知能)プロダクトをクライアントに提供できております。
③ 経験豊富なチームと国内外有数なアカデミアとの連携等の組織体制
当社は、様々なバックボーンを有し、テクノロジーやビジネスに造詣の深い国内外の優秀な人材を確保することで、真にクライアントが求めるプロダクトを提供できるような体制を構築しております。また、当社のビジョンに賛同頂いた、国内外有数のアカデミアの方々と連携・共同研究を行っており、当社独自開発の「LHTM-2」等のLLM等、常に最先端技術を提供できる体制を整えております。
また、当社は業務委託者を積極的に活用することで人材の流動性を確保し、正社員では採用が難しいような高い専門性を持つ人材や当社に最適な人材を世界中から集め、正社員も合わせ、グローバルで90名以上の規模にて事業に取り組んでおります。業務委託者の当社へのコミットメントは様々ですが、2024年6月末現在における業務委託者の在籍状況は次のとおりです。特にエンジニアにおいては契約期間を長期化し、長期のサポートが可能な契約形態、または月40時間に留まらない稼働等、コミットメントを高める施策を講じております。
(注) 1.2024年6月末現在における、業務委託者の過去の契約期間であります。
2.2024年6月単月における、業務委託者の月当たり稼働時間を指します。
④ 当社のコア技術
当社は、要素技術、LLM、インフラストラクチャー等、生成AIのバリューチェーンにおいて必要な技術要素を自社開発・自社保有しております。

<LLMについて>
当社のコア技術でもあり多くのプロダクトにも組み込まれている、独自開発のLLMの種類及び特徴は次の表のとおりです。なお、当社のLLMは、ハルシネーション(LLMが、正当性がなく、事実に基づかない虚偽の回答をしてしまう現象)を極力排除できるよう設計をしており、ハルシネーションの発生確率を自動的に評価できるエンジンも開発しております。
(注) 1.Japanese General Language Understanding Evaluationの略であり、早稲田大学とヤフー株式会社(現LINEヤフー株式会社)の共同研究により構築された、日本語言語理解を図るベンチマークであります。
2.YuzuAIグループが構築した日本語LLMを評価するためのベンチマークを指します。
3.2023年10月時点において、開示されている各ベンチマークとの比較に基づいております。
<インフラストラクチャーの説明>


(2) 当社サービスの特徴・優位性
当社は人工知能(AI)事業の単一セグメントでありますが、当社内のサービス分類として2つの事業区分に分けており、その区分に基づくサービスの特徴・優位性を以下のとおり記載します。
① AI Products事業
当社の「P.A.I.」(パーソナル人工知能)の実現のために研究開発を重ね蓄積させてきた要素技術と、多くの戦略的パートナーとのリレーションを活用した課題発掘力及び優秀なエンジニア陣によるプロダクト開発力、AIの社会実装力を基盤とすることで、多くのAIプロダクトの開発・提供を行っております。
<プロダクト一覧及び説明>






(注) Communication Intelligence「AI GIJIROKU」以外のプロダクトは、主にPoCにより提供されており、PoCにより提供されるプロダクトはAI Solutions事業にて収益計上しております。
(メインプロダクトであるCommunication Intelligence「AI GIJIROKU」)
当社の開発する高精度音声認識技術と日本語最高精度を記録したLLMを組み合わせたソリューションにより、ビジネスシーンの「P.A.I.」(パーソナル人工知能)を提供しています。会議などの発言者の区別をしながらリアルタイムに文字起こしし、自動的に議事録を作成し要約やToDoを纏めるだけではなく、それらコミュニケーションデータをセキュアに保存するデータクラウドソリューションとして価値提供します。
音声認識を利用した文字起こしによる議事録サービスや、AIボットサービス、またChatGPTなどの一般的な物事を熟知する生成AIは多く存在してきておりますが、当社のCommunication Intelligence「AI GIJIROKU」は音声認識×生成AI技術を組み合わせることで、クライアント社内の会議を含む全コミュニケーションデータを記憶したAIを働かせることが可能なソリューションとして他プロダクトとの差別化を図ることに成功しています。
具体的には、次のような特徴があります。
1. パーソナライズ機能
当社のCommunication Intelligence「AI GIJIROKU」において最も優位性のある特徴が「パーソナライズ機能」になります。汎用的な音声認識とは異なり、一人ひとりの単語選択の癖、文脈構成の癖、イントネーションの癖などを学習していくことで一人ひとりに合った音声認識を学習していきます。また、SNSやカレンダーと予め連携しておくことで、その時における発話がどういった意味を持つかを推測しにいくことが可能になっています(例えば、カレンダーに当社との会議が入っている時間帯では、「おるつ」という音を「オルツ」という単語として認識する、など)。固有名詞認識は、一般的な単語よりも複雑で、様々な言語や表記のバリエーションが存在します。したがって、これらの固有名詞を正確に認識することは難しい場合があります。しかしながら、ユーザーはユーザー自身がかかわる固有名詞が正確に認識されることを期待しています。特に会議の議事録などの文書では、人名や会社名、地名などの固有名詞の正確な認識が重要です。認識の不正確さやミスは、信頼性や使いやすさに影響を与えます。固有名詞の誤認識は、文脈や情報の正確性に直接的な影響を与える可能性があります。例えば、誤って認識された人名や会社名は、議事録や報告書の内容を正確に把握するのを難しくします。その結果、ユーザーはシステムの信頼性を失う可能性があり、満足度が得にくくなります。これらの理由によりユーザー満足度を得にくい領域であった固有名詞認識について、これまで数多く存在してきた議事録サービスがマーケットフィットに苦戦した中、当社のパーソナライズ機能は、例えばユーザーのメールやSNSなどのアプリと連携することにより関連する固有名詞を学習させることができるため、ファインチューニングが可能になっています。
2. パーソナライゼーション技術を用いた高い音声認識精度
「P.A.I.」(パーソナル人工知能)の実現を目指し、様々な要素技術を蓄積してきました。これにより、高度な音声認識精度を実現し、個々人の発言を正確に理解することができます。さらに、パーソナライゼーション技術を駆使して、業界ごとに専門用語を認識しやすくすることができます。現在、業種別音声認識ソリューションを15業界分(2024年8月末時点)保有しております。前提として、日本語には同音異義語が多い事、また業界によって、日常使用する表記とは異なる表現方法や、漢字と平仮名の書き分けなどの異なる習慣があります。例えば「こうしょう」という単語は48の同音異義語がある(日本漢字能力検定調べ)ように、複数ある漢字の中でどの漢字が適しているかと判断するために、文脈や意味を理解する必要があります。その文脈や意味で使い分けるためには、業界に特化した音声認識が必要であります。当社の音声認識エンジンは各業界に特化した形にチューニングすることにより、汎用的な音声認識では認識することが難しい同音異義語や専門用語(カタカナなど)を高い精度で認識することができます。業界に応じた膨大な専門用語や言い回し等を学習させることにより、例えば建築業界向けの「建築GIJIROKU」上は「かわら」をそのまま平仮名で表記せず、さらに「河原」に誤変換することなく「瓦」に変換するといった、各業界に特化した形で追加のチューニングを加えることで、一層精度を高めることが可能であります。
当社のパーソナライズ技術又は業界特化のチューニングを施したものを総称して「パーソナライズドモデル」と称しております。
当社が有する顧客基盤の一例として、当社が有する2パターンのエンジンを用いた、建築業界及び医療業界の業種別音声認識ソリューションにおける音声認識例が以下のとおりです。具体的には、当社における高精度音声認識エンジンである「パーソナライズドモデル」(注1)及び当社のパーソナライズ技術を駆使していない又は業界に特化していない汎用的なエンジンである「平均モデル」(注2)の2パターンであります。
なお当社では、「平均モデル」そのままでのサービス展開は行っておらず、「平均モデル」に当社の独自開発のLLMである「LHTM-2」を利用してSNSやメール、辞書データからの自動学習や声紋判断による話者特定といったパーソナライズ技術を施し最適化することで、高精度音声認識エンジンのCommunication Intelligence「AI GIJIROKU」としてユーザーへ提供しております。利用する度に学習し、文字起こしの精度が向上するため、ユーザーは常に最新の技術を享受できます。
<当社が開発した業界別音声認識ソリューション例>
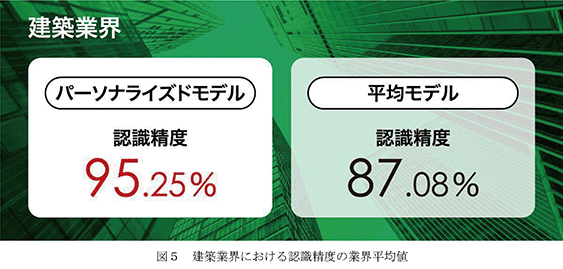
建築 GIJIROKU
建築業界における「パーソナライズドモデル」の認識精度の業界平均値が95.25%、「平均モデル」の業界平均値は87.08%であります。
上記の「パーソナライズドモデル」及び「平均モデル」の業界平均値の水準に最も近似した事例が以下のとおりです。

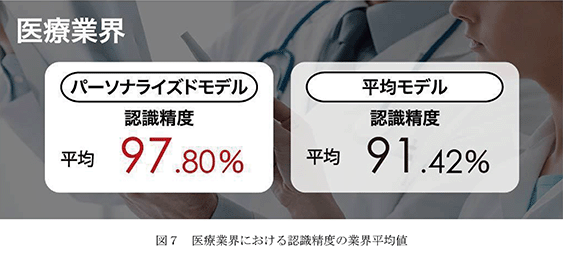
医療 GIJIROKU
医療業界における「パーソナライズドモデル」の認識精度の業界平均値が97.80%、「平均モデル」の業界平均値は91.42%であります。
上記の「パーソナライズドモデル」及び「平均モデル」の業界平均値の水準に最も近似した事例が以下のとおりです。

(注) 1.「パーソナライズドモデル」とは、業界特化エンジンを含む、高度な文脈理解のための最適化が施された当社の高精度音声認識エンジンのことであります。
2.「平均モデル」とは、各業界に特化した同音異義語や専門用語(カタカナなど)を学習していない汎用的なエンジンのことであります。
3.建築業界及び医療業界の業種別音声認識ソリューションにおける音声認識は、当社にて実験室内(通常オフィス環境)で音声を用い、「パーソナライズドモデル」及び「平均モデル」のエンジンにて、1個のデータ当たり20回ずつのテスト実験を行ったものであります。
4.建築業界における音声認識は、2024年7月時点における394個の実験データに基づくものであります。建築業界全体における394個の実験データの、「パーソナライズドモデル」の認識精度の平均値は95.25%、「平均モデル」の認識精度の平均値は87.08%であります。
5.医療業界における音声認識は、2024年6月時点における124個の実験データに基づくものであります。医療業界全体における124個の実験データの、「パーソナライズドモデル」の認識精度の平均値は97.80%、「平均モデル」の認識精度の平均値は91.42%であります。
6.認識精度の算出方法は、CER(文字誤り率)を100%から引いた値で、原文と一致している文字数のパーセンテージで表示しております。
7.読み上げ原文からの認識間違いを赤字で表記しております。
当社は英語よりも同音異義語の多さを有する日本語において、高い音声認識精度を有しております。さらに、当社は2023年6月に人力による文字起こし事業を事業譲受しており、AI Solutions事業において、人力(Human-in-the-Loop)による文字起こしサービスを展開し、完璧な精度を有する議事録の提供が可能であります。
3. 多言語に対応
英語、中国語、スペイン語等、35ヶ国語(本書提出日現在)に対応したリアルタイム翻訳機能により、指定した言語で会話が記録されます。また、音声合成技術を活用して、AIに翻訳テキストを発話してもらうことが出来るサービスを提供しており、ユーザー間のコミュニケーションを取りやすくするメリットを有しております。
4. Zoom連携が可能
Zoomビデオコミュニケーションズが提供するクラウドコンピューティングを使用したWeb会議サービスである「Zoom」と連携することができます。会議やウェビナーでの会話をリアルタイムで画面にテキスト化して字幕として表示でき、通話終了後は議事録を自動保存します。
5. パーソナルエージェント機能
高精度な音声認識と、当社が保有する高い日本語精度を誇るLLMを組み合わせることで、社内外で交わされる商談や会議の全データをテキストデータとして書き起こし、保管し、そのデータを基に社内外のコミュニケーションをとることができます。例えば、当社プロダクトである「altBRAIN」との連携により営業が行った全商談の要約を役員に随時共有したり、ある商談についての次の提案内容をドラフトしたり、全開発会議を把握することである開発における意思決定過程の透明性を高くしたりすることができます。
<課金体系>
課金体系は次のとおりです。当社では、法人のチームプランを中心にサービスを展開しておりますが、足元では法人のビジネスプランの対象となるエンタープライズ向けのセールスチームを立ち上げ、ビジネスプランの獲得に注力しております。
② AI Solutions事業
AIの活用を検討するクライアントに対して、コンサルティング、PoC、本番開発から協業販売までのプロジェクト遂行の支援をしております。当社の設立以降、継続して推進してきた事業であり、かつ当社が最も得意とする分野でもあります。「P.A.I.」(パーソナル人工知能)の開発を目指す上で蓄積させてきた要素技術及びそれらの統合ノウハウを活用することで、当社が「カンパニゼーション」(※)と呼ぶクライアントごとのデータ・特徴に合わせたプロダクト活用もしくはインフラの構築などのニーズを捕捉していきます。AI Solutions事業ではクライアントが直面する課題の生の声を聞くことが可能であり、それらの課題と当社の「P.A.I.」(パーソナル人工知能)要素技術が合わさることで、現在の労働集約的な状態を打開するようなプロダクトの創出に繋げることが可能です。各クライアントに存在する属人的なノウハウや作業過多な業務をAI技術で自動化もしくは効率化を行うことで、より創造的な時間を創出します。また、今後はAI Products事業で関係を持った企業群を本AI Solutions事業のリード顧客としてみなしていくことで、事業間の好循環を回し、更なる収益機会の拡大を図ります。
(3) 当社とAI領域で連携するグローバルパートナー
当社は、LLM等の当社が有する幅広いAI技術と、株式会社キーエンスのノウハウやデータに基づく合理的な企業運営の知見を合わせ、新たなソリューションを提供することを目指し、資本業務提携を行っております。さらに、NVIDIA Corporationが展開するスタートアップ支援プログラム「NVIDIA Inception Program」にてパートナー企業に認定されており、業務連携を通じ「EMETH」や「EMETH GPU POOL」を強化してまいります。またその他にも、デロイトトーマツグループのデロイトトーマツコンサルティング合同会社と生成AIの社会実装を目的、Stability AI Japan株式会社とは音声・画像・映像における生成AIのユースケース確立を目的、Databricks Inc.とはデータ構造化及びAI/DX化の加速を目的として業務連携を行っております。このように、グローバルに活躍するパートナーとの連携を多数実施しており、生成AI領域における確固たるポジショニングを築いているものと理解しております。
(事業系統図)
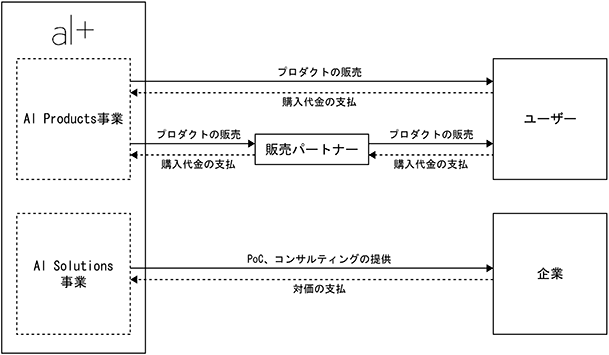
(注) 「販売パートナー」とは、販売店契約に基づき取引を行う「販売店」の当社における呼称であります。
※用語解説
本項「事業の内容」において使用する用語の定義については、次のとおりであります。
4 【関係会社の状況】
該当事項はありません。
5 【従業員の状況】
(1) 提出会社の状況
2024年8月31日現在
(注) 1.従業員数は就業人員であり、臨時従業員数(契約社員及びアルバイト・パート社員を含む、派遣社員は含まない)は、年間の平均雇用人員を〔 〕内に外数で記載しております。
2.平均年間給与は、賞与及び基準外賃金を含んでおります。
3.最近日までの1年間において従業員数が増加しておりますが、これは主に業務拡大に伴う採用の増加と、株式会社IPパートナーズよりコエラボ事業及び安起こし事業の買収に伴い増加したことなどによるものであります。
4.当社は人工知能(AI)事業の単一セグメントであるため、セグメント情報との関連については、記載しておりません。
(2) 労働組合の状況
当社において労働組合は結成されておりませんが、労使関係は円満に推移しております。
(3) 管理職に占める女性労働者の割合、男性労働者の育児休業取得率及び労働者の男女の賃金の差異
当社は、「女性の職業生活における活躍の推進に関する法律(平成27年法律第64号)」及び「育児休業、介護休業等育児又は家族介護を行う労働者の福祉に関する法律(平成3年法律第76号)」の規定による公表義務の対象ではないため、記載を省略しております。